Cash for COVID
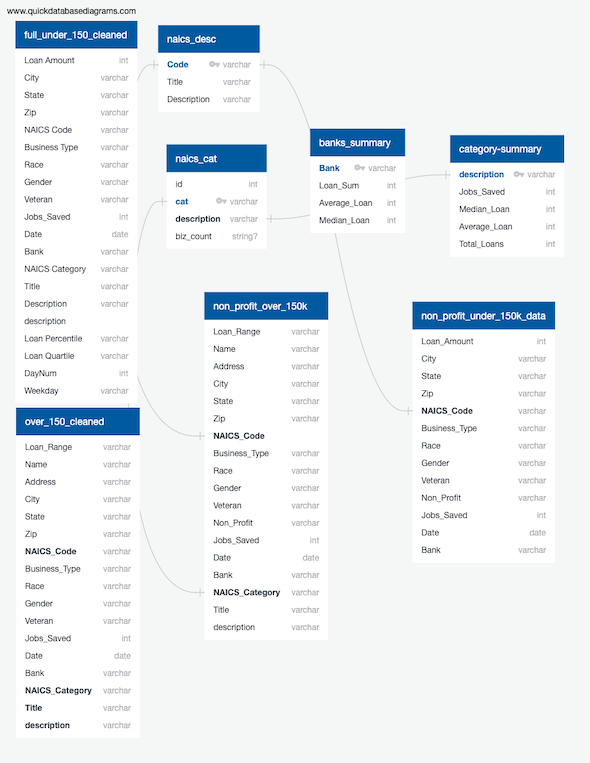
The data pipeline
Wrangling the data
Over 50 CSV files were merged using a Python programming script to automate the process. Spark was leveraged to speed up processing 5 million loan records and application of random forest machine learning algorithm and visualizations were produced with Python Pandas. Normalization was started using Python and continued in SQL. Tableau provides interactive visualizations which are hosted in Tableau Public and linked in the navigation.
The code
GitHub repository: Cash for COVID, Clean Machine Pipeline.
Original data source: Small Business Association.
Cleaned CSV files: P.P.P. Tables.
The data and approach
The information came from the SBA in two formats: The largest dataset numbering 4.3 million rows provided loan amount information but the borrower names were withheld. Enterprise names were revealed for lending above $150k and the debt was put into categorical range such as $3 to $5 million instead of a specific tally.
Lending institution, business type and geographic location were consistent throughout both datasets. Approximately 5% of the borrowers supplied gender, racial identity and military status. Even though that is a small percentage relative to the rest of the information, it still provides almost a half of a million responses and the hope is that it represents general trends so it is preserved as an additional dataset.
Business type information came in the form of NAICS identification numbers that were split into general categories for aggregate data and kept whole for granular analysis. The image below shows an example in which a SQL query using several of these codes to retrieve information for personal care services such as hair salons and massage services in California.

Still taking shape
At time of this writing, it seems likely that a second round of these loans will be issued, and guidelines for forgiveness of debt is being negotiated in Congress, so it is entirely possible that this project will be duplicated as a new round of small business stimulus data is funneled through the code and processes outlined above.